Eckart 和 Young 的贡献使得我们能用低秩的矩阵来最佳近似原高维矩阵 A
范数 norm
在介绍 Eckart-Young 理论 之前,我们首先需要了解什么是 范数 norm,范数是描述对象有多 “大” 的 标量
向量范数
假设 v∈Rn,有下列常用的 向量范数
-
ℓ2:2-范数,可能是最为常见的范数,它就是向量各分量 平方和的平方根
∥v∥2=v12+⋯+vn2
-
ℓ1:1-范数,向量各分量 绝对值之和,采用这个 范数 作为 正则项 一般意味着 稀疏性
∥v∥1=∣v1∣+⋯+∣vn∣
-
ℓ∞:无穷范数,向量绝对值最大的分量
∥v∥∞=nmax∣vi∣
矩阵范数
设 A∈Rm×n,有下列常用的 矩阵范数
-
ℓ2:矩阵 2-范数,等于矩阵最大的 奇异值
∥A∥2=σ1
- 奇异值 由 SVD 得到,根据约定,最大的奇异值被排在 σ1
-
ℓF:矩阵 Frobenius 范数,它是矩阵所有元素 平方和的平方根
∥A∥F=a112+⋯+a1n2+⋯+an12+⋯+amn2
- 注意,虽然这很像向量的 2-范数,但是矩阵的 2-范数 是最大奇异值
-
ℓ∗:矩阵 核 Nuclear 范数,矩阵所有 奇异值 之和
∥A∥∗=σ1+σ2+⋯+σr
-
这个范数类似向量的 1-范数,将为矩阵带来 稀疏性,由于奇异值一定为正,所以我们不需要为他们取绝对值;而与向量的 1-范数 相比,得到稀疏性的对象不同
- 向量的 1-范数 将 坐标值 变得稀疏,很多分量直接变为 0
- 矩阵的 核范数 让 奇异值 变稀疏(很多奇异值变 0),从而得到 低秩矩阵;但矩阵的元素未必稀疏
-
因此矩阵的 核范数 常常与 稀疏重建 有关,这也称 压缩感知 compress sensing
- 对婴幼儿的 核磁共振 MRI 尝尝采用这一技术,因为长时间的照射将对它们身体产生负面影响,必须从稀疏的采集数据中还原出有意义的图景
- 采用 核范数 作为正则惩罚的方法赢得了 Netflix 电影评分推荐系统大奖
范数不等式
有两个式子,是上述范数都满足的(或者说只要是真正的范数,就应该满足下面的两条性质),下述的 v, w 可以是 向量,也可以是 矩阵
-
齐次性
∥cv∥=∣c∣⋅∥v∥
标量可以被提出范数计算,但是要取其 绝对值
-
三角不等式
∥v+w∥≤∥v∥+∥w∥
实际上,只要在 “任意阶张量” 的空间上用的是 真正的范数,那么该范数必然满足上述两条性质
计算上,高阶张量的谱/核范数精确计算一般是 NP-hard,这不影响它们作为范数的公理性质成立
Eckart-Young 理论
我们知道,对于 秩 为 r 的矩阵 A∈Rm×n,可以根据其 SVD 结果,将其写为
A=UΣV⊤=σ1u1v1⊤+⋯+σrurvr⊤
也就是 r 个 秩 为 1 矩阵之和的形式
如果我们只取前 k 项,我们得到
Ak=UkΣkVk⊤=σ1u1v1⊤+⋯+σkukvk⊤
Eckart-Young 定理 告诉我们,对于任意 秩 为 k 的矩阵 B 下面的不等式 一定成立
∥A−B∥≥∥A−Ak∥
- 这里的范数 ∥⋅∥ 可以是上面提到矩阵范数中的任意一种,都成立
也就是说,Ak 一定是 秩 为 k 的矩阵中,对 A 对最佳近似,因为 Ak 到 A 的 距离(范数) 是最小的
从直觉上来说,SVD 得到的 Σ 是 对角矩阵,取前 k 项就是取前 k 个对角元素,显然不会存在比仅有前 k 个对角元素的对角矩阵 范数(仅有前 k 个对角元素的矩阵到原完整对角矩阵的距离)更小的矩阵,而 U 和 V 是 正交矩阵 (可以认为是纯旋转或反射矩阵) ,它们不会改变 范数 大小
PCA 和 最小二乘 的区别
最小二乘(OLS) 和 PCA/正交回归/总最小二乘(TLS)一般并不等价,下面用二维来举例说明(但可以推广到高维)
OLS 指 Ordinary Least Squares 也就是 普通最小二乘(回归),与之对应还有 WLS=加权最小二乘、GLS=广义最小二乘、TLS=总最小二乘/正交回归
- OLS(y 对 x 的回归):最小化 竖直 方向误差
a,bmini∑(yi−(a+bxi))2
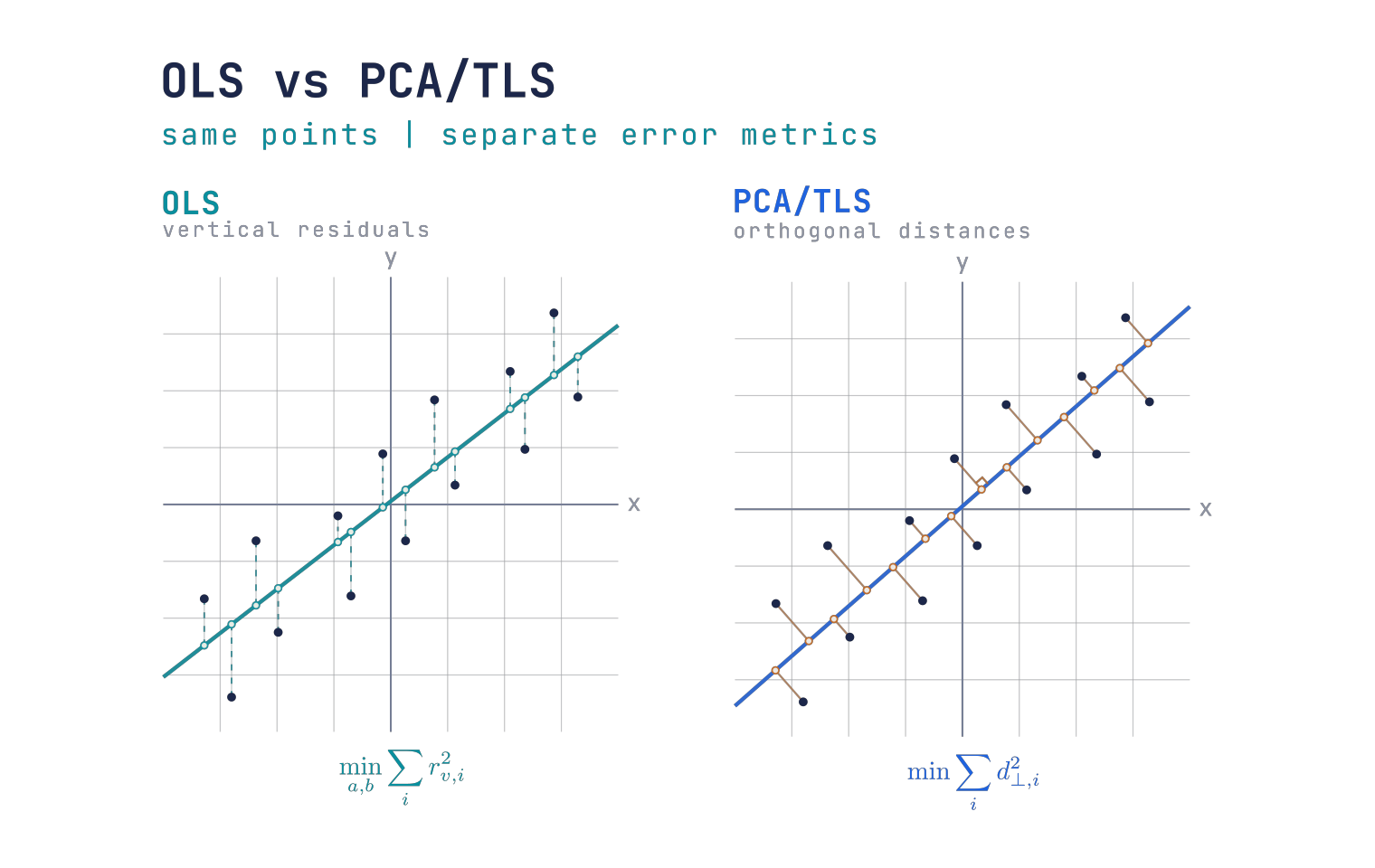
 同一组点中,OLS 度量竖直残差,PCA/TLS 度量到拟合直线的正交距离。
同一组点中,OLS 度量竖直残差,PCA/TLS 度量到拟合直线的正交距离。
- PCA/TLS(正交回归):最小化到直线的 垂直 距离
a,bmini∑1+b2(yi−(a+bxi))2
- 注意,与 OLS 相比多了一个依赖于 斜率 b 的分母 1+b2
很多人认为二者的差别在于是否允许 截距,但实际上两者都允许截距;当把数据 中心化 后,二者最终的最优直线都会通过 质心 (xˉ,yˉ),因此截距就是
a=yˉ−bxˉ
所以 “是否有截距” 不是本质区别,误差度量方向 才是
点到直线 y=a+bx 的 垂直距离 与 竖直残差 的关系是
d⊥,i=1+b2∣yi−(a+bxi)∣=∣rv,i∣⋅cosθ,cosθ=1+b21
也就是说,OLS 优化的是 ∣rv,i∣,而 PCA 优化的则是 ∣rv,i∣⋅cosθ,可以发现,θ 取决于 b,b 在我们执行优化时会改变的,它并不是常数,而是 PCA 优化目标的一部分,所以二者的优化目标不相同,所以两种方法并不等价
1) 点到直线的垂直距离公式
把直线写成标准的 一般式 Ax+By+C=0,点 (xi,yi) 到这条线的(无符号)距离是
d⊥=A2+B2∣Axi+Byi+C∣.
理由:取法向量 n0=(A,B),其单位向量 n=∣n0∣n0 直线可写成
n⋅z=−∣n0∣C;点 p=(xi,yi) 到直线的有符号距离是 n⋅p+∣n0∣C,取绝对值即上式。
应用到 y=a+bx(等价于 bx−y+a=0),得到
A=b, B=−1, C=a⇒d⊥,i=b2+1∣bxi−yi+a∣=1+b2∣yi−(a+bxi)∣.
2) 为何 cosθ=1+b21
令直线 y=a+bx 的一个法向量为 n0=(b,−1)。单位法向量
n=1+b2(b,−1).
竖直单位向量是 ey=(0,1)。两者的夹角 θ 的余弦为
cosθ=ey⋅n=(0,1)⋅1+b2(b,−1)=1+b21.
(取绝对值只为保证角度在 0∼π/2 内。)
3) 垂直距离与竖直残差的关系
在同一 xi 处,点到直线的竖直残差是
rv,i=yi−(a+bxi).
从点 (xi,yi) 向下画到直线的竖直线段向量为 u=(0,rv,i),其长度 ∣u∣=∣rv,i∣。
将 u 在单位法向量 n 上做投影,投影长度就是真正的最短距离:
d⊥,i=∣u⋅n∣=∣u∣⋅cosθ=∣rv,i∣⋅1+b21.
这与第一部分用一般式推导的结果一致,也点明了关键:该因子依赖斜率 b,所以 OLS(最小竖直残差平方和)与 TLS/PCA(最小正交距离平方和)一般不会得到同一条线。
如果在 高维 情况下,则是
- 预测型:最小二乘 OLS(最小化“竖直残差”)
- 对称型:正交回归 / 总最小二乘 TLS(最小化“到超平面的正交距离”),而 TLS 的解等价于对中心化数据做 PCA 得到的子空间
在二维把 TLS 的 “最佳线” 写成方向向量时,它就是 PCA 的第一主成分方向(线的法向量对应第二主成分)
如果从机器学习的角度来看,也可以认为 OLS 是 监督学习 而 PCA 是 无监督学习
- OLS:有标签 y,学的是从 X→y 的映射,最小化竖直残差 ∣y−Xβ∣2 ——典型的监督学习。
- PCA:只看 X 的结构(协方差),找最大方差的正交方向,不用 y ——无监督学习。
但有两个常见“混合”情形要注意:
- PCR(主成分回归):先做 无监督 的 PCA 得到 Z=XW,再对 y∼Z 做 监督 的 OLS。
- TLS/正交回归:用到 y(在 [X ∣ y] 上做 SVD),属于监督的回归,但损失是正交距离,几何上等价于对增广数据做 PCA 找超平面。
所以:若比较的是 OLS vs.(在 X 上的)PCA 第一主成分方向,确实是“监督 vs 无监督”;若比较 OLS vs TLS,那二者都属于监督回归,只是误差度量不同。
何时两者会一致?
只有当数据几乎完全落在一条/一张线性子空间上 (数据完美线性关系,无噪声或噪声仅沿直线方向),OLS 与 TLS/PCA 才会给出同一条线/超平面
实践指引
- 想 预测 y,且认为噪声主要在 y:用 OLS
- 两侧都有测量误差、或想得出 对称几何关系:用 TLS / PCA 子空间
- 高维想做低秩近似:直接用 PCA(前 (k) 个主成分) 拟合子空间;若还要预测,可在此子空间内再做回归(PCR/PLS)