介绍最小二乘问题
伪逆与普通逆矩阵的关系
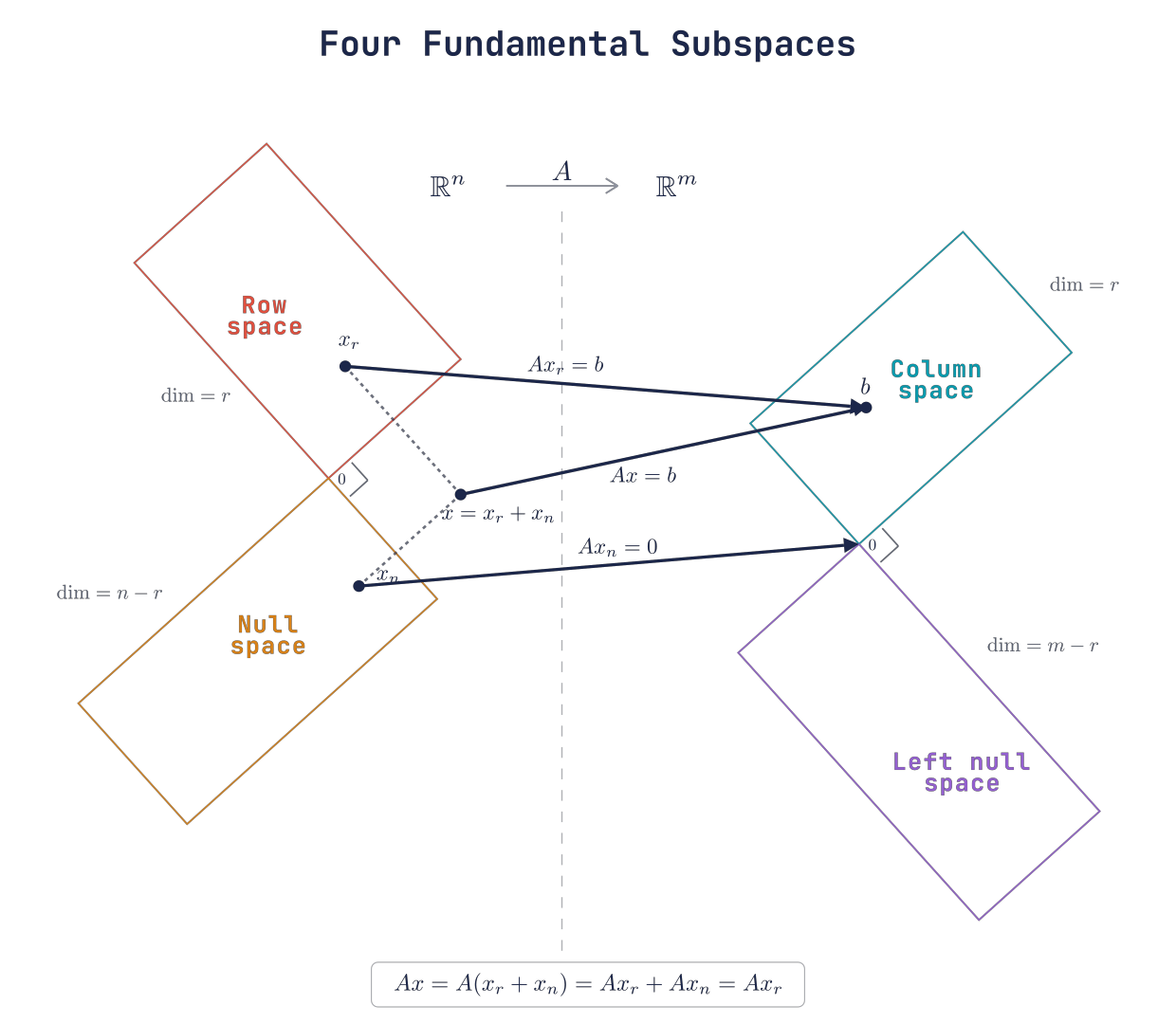
 A 把 row space 中的分量映到 column space,同时把 null space 中的分量压到 0,因此 Ax=A(x_r+x_n)=Ax_r。
A 把 row space 中的分量映到 column space,同时把 null space 中的分量压到 0,因此 Ax=A(x_r+x_n)=Ax_r。
若有矩阵
A∈Rm×n
我们可以把 A 看作是 Rn→Rm 的线性变换,它接受 Rn 的向量输出 Rm 的向量,我们知道它是 不可逆 的,即 A−1 不存在,这是因为
-
当 m<n
- 此时 A 是一个 列数比行数多 的 矮胖 矩阵
- 此时可以认为 未知数比方程多 (欠定)
在这种情况下,A 的 行空间 不足以撑满整个 Rn,这是因为
r=rank(A)≤m<n
- 矩阵的秩不可能超过 min(m,n)
所以 A 的 零空间 维度是大于零的,因为
rank(kerA)=n−r
由于
r<n
所以
rank(kerA)>0
即其中一定不止含有 零向量,于是 A 将 Rn 中的 多个向量 映射到 Rm 的 零向量,而我们不可能从 零向量 反向解压出映射前是哪些向量,所以我们无法得到 逆变换
可以认为 非行满秩 的 方阵 也是这种情况
-
当 n<m
- 此时 A 是一个 行数比列数多 的 高瘦 矩阵
- 此时可以认为 未知数比方程少 (过定)
由于此时
rank(A)≤n<m
因为 列空间 只有 n 维,且小于目标空间 m 维,所以它无法铺满整个目标空间,也就是说 目标空间 中一定存在一些向量是在 源空间 中找不到对应的,自然也就不可能建立一个 逆变换
也可以看看线性代数笔记中关于 伪逆 的详细讨论
但是如果我们无论如何还是想构造 A 的某种 “逆变换” 该怎么办?显然我们需要做出一些妥协,具体来说,对于 正向变换,也就是 Rn→Rm
- 对于 Rn 内位于 行空间 中的向量,我们将它映射到 Rm 中的 列空间 内
- 对于 Rn 内位于 零空间 中的向量,我们将它映射到 零向量
对于 逆向变换,也就是 Rm→Rn
- 对于 Rm 内位于 列空间 中的向量,我们将它映射回 Rn 中的 行空间 内
- 对于 Rm 内位于 左零空间 中的向量,我们将它映射回 零向量
我们称完成这种 逆变换 的矩阵为 Moore-Penrose 伪逆 A†,可以看作 A 在 可逆部分 上取逆,在其余部分上取零
如果矩阵 A 本身是可逆的,那么它的 伪逆 就会退化为普通逆矩阵,也就是
A†=A−1.
原因是当 A−1 存在时,矩阵满足
A−1A=AA−1=I.
也就是说,不存在 列空间 之外的向量,因此在这种特殊情形下,伪逆 与普通逆是一致的
找到伪逆的方法
我们已经有了 伪逆 应该做什么的指导思想,接下来就是找到一种具体的执行方案来找到它
现代最为流行且数值稳定的方法是通过 奇异值分解 SVD,它对于任意矩阵都是存在的
A=UΣV⊤
可以得到 伪逆 为
A†=VΣ†U⊤
这里的 Σ† 是
Σ†=σ110⋮0⋮00σ21⋮0⋮0⋯⋯⋱⋯⋮000⋮σr1⋮0⋯⋯⋮⋯⋱⋯00⋮0⋮0n×m
它乘以 Σ 会得到前 r 个对角线元素为 1,其余对角线元素全为 0 的矩阵,这是最接近 单位矩阵 的情况了
可以发现之前讨论的妥协版 正向/逆向 变换,实际上就是向矩阵的 行空间 或 列空间 进行投影
AA†A†A=UΣV⊤VΣ†U⊤=ΣΣ†=[ † ]m×m⟹向列空间投影=VΣ†U⊤UΣV⊤=Σ†Σ=[ † ]n×n⟹向行空间投影
最小二乘解
矩阵 A 的逆 A−1 不存在可以理解为矩阵方程
Ax=b
无解,因为
x=A−1b
而 A−1 不存在,这种问题很常见,但是我们可能仍然想找一个 x 让 Ax 尽量靠近 b,用数学语言可以表述成,使得
∥Ax−b∥
尽可能的小,这里 ∥⋅∥ 表示的是 “距离” 或者 “模长” 也可以说是 范数,也就是说我们必须找到一种方式来衡量 Ax 到 b 的距离,最为常见的方式是 2-范数,对于向量来说是平方和的平方根
∥x∥2=x12+x22+⋯+xn2=x⊤x
所以我们要使
∥Ax−b∥2
尽量最小,不过通常为了方便,也可以等价的去最小化它的平方
∥Ax−b∥22
因为平方不会改变最小值点,我们可以继续把它展开成一个关于 x 的 二次型
∥Ax−b∥22=(Ax−b)⊤(Ax−b)=(x⊤A⊤−b⊤)(Ax−b)∵(Ax−b)⊤=x⊤A⊤−b⊤=x⊤A⊤Ax−x⊤A⊤b−b⊤Ax+b⊤b展开=x⊤A⊤Ax−2b⊤Ax+b⊤b∵x⊤A⊤b=b⊤Ax 都是标量
所以最终合并展开的式子就可以认为是我们需要进行优化的 目标函数
f(x)=x⊤A⊤Ax−2b⊤Ax+b⊤b
按照常规方法,我们需要对该函数进行求导,并令导数为 0 来寻找可能的 极值
需要注意的是,这里 f(x) 是一个 标量值 函数,因为它输入一个向量 x,输出一个 标量,可以写成
f:Rn→R,x↦f(x)
或者,我们可以把它直接理解为 多元函数
f(x1,x2,⋯,xn):Rn→R
所以对它求导就是在求 f 的 梯度,遵循多元函数求导法则
第一项
对于第一项
x⊤A⊤Ax
如果记 M=A⊤A,由于 A⊤A 是 对称矩阵
(A⊤A)⊤=A⊤A
所以有
∇x(x⊤Mx)=(M+M⊤)x=(M+M)x=2Mx
这只有在 M 是 对称矩阵 时才成立,显然
M=M⊤
而对于
∇x(x⊤Mx)=(M+M⊤)x
我们可以设
f(x)=x⊤Mx
若 x∈Rn,则可以写出它的分量形式
x=x1x2⋮xn
那么我们可以写出 f(x) 的逐分量计算形式
f(x)=i=1∑nj=1∑nxiMijxj
-
注意在进行这个推理的时候,我们只要求 M 是 Rn×n 的 一般方阵 并不要求它是 对称 的,所以这里的 求和上限 都是 n
-
若 M 是 非方阵,那
x⊤Mx
不一定是合法二次型
现在我们可以对某个分量 xk 求 偏导
∂xk∂f=i,j∑n∂xk∂(xiMijxj)
因为 Mij 是常数,所以只有当 i=k 或 j=k 时才会有贡献,于是可以分为两部分讨论
∂xk∂f=j∑nMkjxj+i∑nxiMik
- 注意对于 乘积 x⊤Mx 求导,需要对左右的 x 各求一次,然后将它们相加,因为它们都有可能依赖 xk
第一项就是 M 的第 k 行乘以 x,也就是
(Mx)k
而第二项则是 M 的第 k 列乘以 x,即
(M⊤x)k
所以
∂xk∂f=(Mx)k+(M⊤x)k
如果我们对 x 的所有分量都执行这个过程,而不仅仅是 xk 那么我们就可以得到
∇x(x⊤Mx)=(M+M⊤)x
更直观一点的理解,也可以把
x⊤Mx
看成“左边一个 x”和“右边一个 x”各贡献一次导数:
- 左边那个 x 求导,给出 Mx
- 右边那个 x 求导,给出 M⊤x
所以总共就是
Mx+M⊤x
如果 M 对称,两边贡献一样,于是就是
2Mx
第二项
−2b⊤Ax
我们要求它对于 x 的梯度
可以发现 b⊤A 是一个 行向量 也可以写成 列向量 转置的表示方式
(A⊤b)⊤
因为这一项对 x 来说其实就是一个 线性函数
先把它改写一下
b⊤Ax
注意矩阵乘法结合后
b⊤A
是一个行向量,所以整个式子就是
(b⊤A)x
也可以写成
(A⊤b)⊤x
因为
(b⊤A)⊤=A⊤b
所以它本质上就是标准形式
c⊤x其中c=A⊤b
而我们知道
∇x(c⊤x)=c
因此
∇x(b⊤Ax)=A⊤b
再乘上前面的 −2,就得到
∇x(−2b⊤Ax)=−2A⊤b
到这里第二项的梯度就已经出来了,接下来把它和第一项合并起来,就能得到最小二乘问题的一阶最优条件
从目标函数到法方程
我们前面把目标函数写成了
f(x)=x⊤A⊤Ax−2b⊤Ax+b⊤b
因此它的梯度就是
∇xf(x)=2A⊤Ax−2A⊤b
这里最后一项 b⊤b 与 x 无关,所以导数为 0
令梯度为零,就得到
2A⊤Ax−2A⊤b=0
两边同除以 2
A⊤Ax=A⊤b
把最优解记成 x^,就得到
A⊤Ax^=A⊤b
这就是 normal equation,也就是 正规方程
直观理解
这件事本质上是在解
Ax≈b
但很多时候这个方程组并没有精确解,比如方程数太多,或者数据本身带有噪声
于是我们退一步,不再要求 Ax=b 完全成立,而是让误差向量
Ax−b
尽量小,这就是 最小二乘 的意思
从法方程的形式也能看出这一点:它并不是直接在解原方程,而是在寻找让残差最小的那个 x