具体探讨一下向量和矩阵的 范数 norm,也就是对向量或矩阵 大小 的度量
向量范数
向量范数指对向量 大小 的度量
2-范数
可能是最为常见的范数,是向量 所有分量平方和的平方根
∥v∥2=v12+v22+⋯+vn2
1-范数
向量 所有分量绝对值之和
∥v∥1=∣v1∣+⋯+∣vn∣
∞ -范数
向量的 最大分量绝对值
∥v∥∞=max∣vi∣
p-范数
以上三个范数实际上都属于 p 范数的特例
∥v∥p=(i=1∑n∣xi∣p)p1p≥1
- 当 p=2 得到 2-范数
- 当 p=1 得到 1-范数
- 当 p→∞ 得到 ∞-范数
p-范数 均满足 三角不等式 和 齐次性,是真正的 范数
0-范数
这个范数不能满足 三角不等式 和 齐次性,所以它并非真正的范数,但是它仍然对于衡量 向量 的 稀疏性 很有用,因为它的定义是向量 非零元素分量的个数
∥v∥0=非零元素个数
S-范数
这是指一个由 对称正定矩阵 S (复数情况则为 Hermitian 矩阵) 诱导的范数,定义为向量 二次型的平方根
∥v∥S=v⊤Sv(复数情况则为 v∗Sv)
- 用 平方根 可以满足 齐次性,即 ∥2v∥S=2∥v∥S
- 如果 S=I,显然将会退化回 2-范数,可以认为就是把 2-范数 用一个 正定矩阵 做了 “拉伸/缩放/旋转” 的加权版
向量范数在二维空间的几何图形
画出不同向量范数在 2D 中 ∥v∥=1 的图像,可能会有助于理解
-
2-范数
∥v∥2=1⟹v12+v22=1
这显然是一个圆的图像
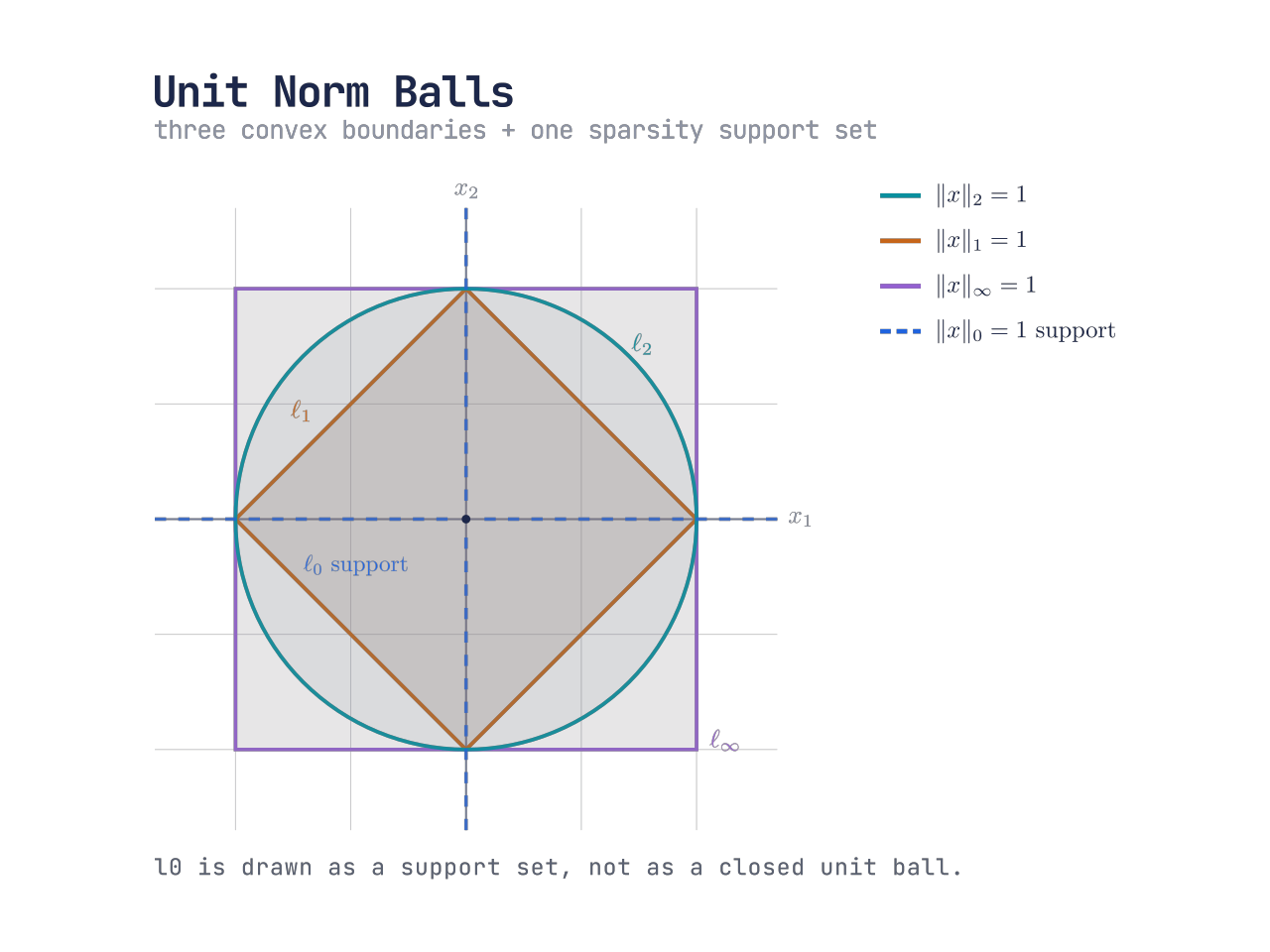
 前三条闭合边界是真正范数的单位球;ℓ₀ 不是范数,这里只把 ‖x‖₀ = 1 的坐标轴支撑集作为对照。
前三条闭合边界是真正范数的单位球;ℓ₀ 不是范数,这里只把 ‖x‖₀ = 1 的坐标轴支撑集作为对照。
-
1-范数
∥v∥1=1⟹∣v1∣+∣v2∣=1
这将在二维平面上形成一个菱形
-
∞-范数
∥v∥∞=1⟹max∣vi∣=1
这表示,向量的最大分量绝对值必须是 1,这会形成一个正方形
-
0-范数
∥v∥0=1⟹只含有一个非零分量
这表示,向量只能有一个 非零分量,显然它必须位于坐标轴上 (原点除外,因为它有两个零分量)
严格地说,这不是和前三者同类的 单位球边界,而是一个不闭合、不有界的坐标轴支撑集
可以发现,所有 p-范数 (上图中的 2-范数、1-范数 和 ∞-范数),都有一个良好的性质:它们都是 凸 Convex 的,这也是为什么 p-范数 要求 p≥1,因为一旦 p≤1,就将失去这种性质
这就是大名鼎鼎的 凸优化
-
S-范数
∥v∥S=1⟹v⊤Sv=1
这个范数有些特殊,因为它形成的图像会随着不同 正定矩阵 S 而改变,例如若 S=I 将直接退化为 2-范数
如果使用别的 正定矩阵,例如
S=[2003]
那么将产生一个被拉伸的椭圆
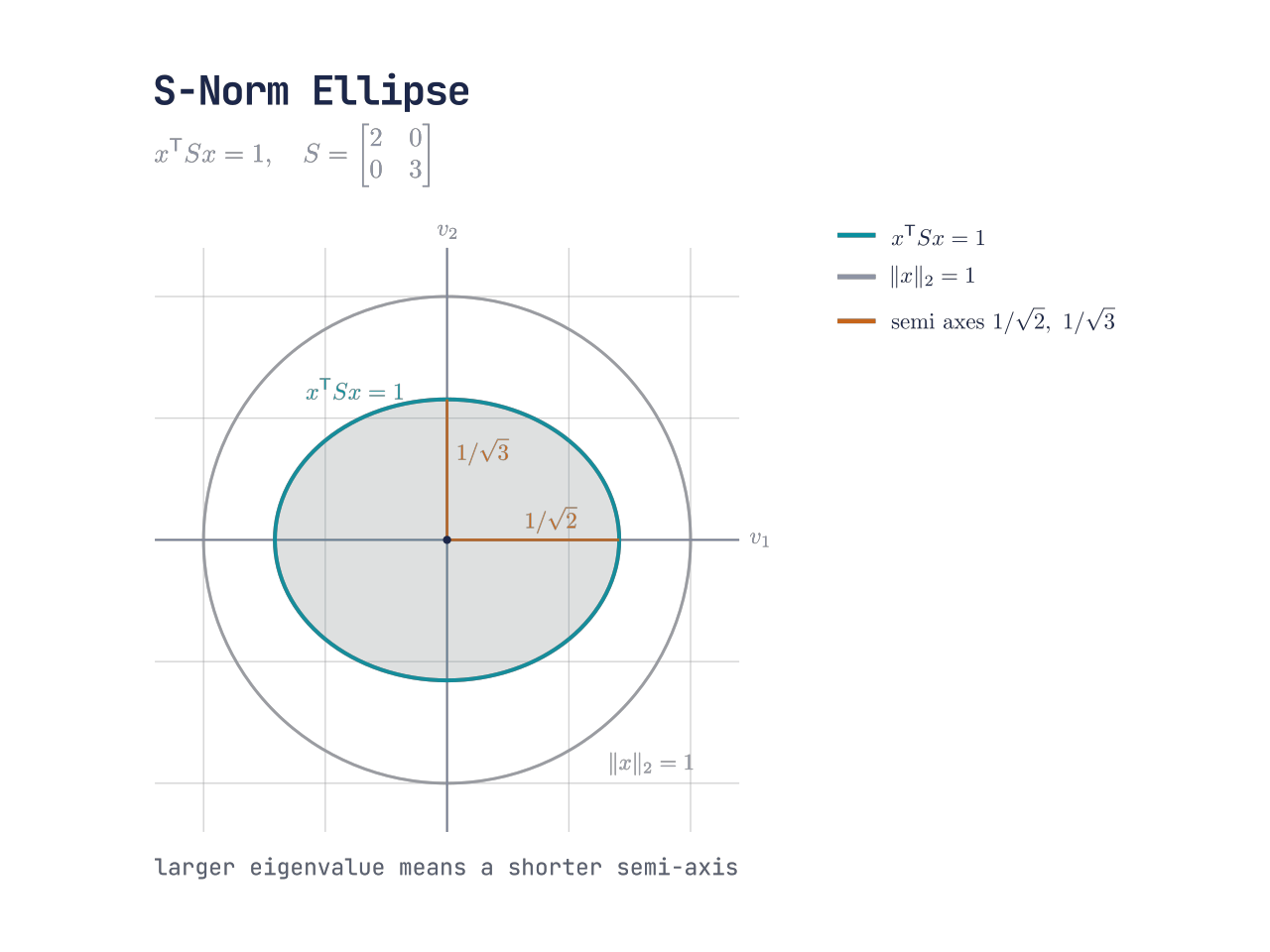
 S-norm 的单位球边界是 x^T S x = 1;在 eigenvalue 更大的方向,半轴更短。
S-norm 的单位球边界是 x^T S x = 1;在 eigenvalue 更大的方向,半轴更短。
因为此时
∥v∥S=1⟹2v12+3v22=1
优化在二维空间中的图景
很多时候,我们处理的优化问题本质上是在针对某个 矩阵方程组 最小化某个向量的 范数
也就是说,对于矩阵方程
Ax=b
找到使得方程成立的 最小 的 x,而 b 是给定已知的,这可以表述为 优化问题
Ax=bmin∥x∥
此时,若使用不同的 范数 来衡量 x 的 “大小”,优化将得到不同的结果
假设我们在二维中有个简单的方程需要进行优化
c1x1+c2x2=b
注意这并非矩阵方程,式子中的量均为 标量
那么我们的优化式可以写为
c1x1+c2x2=bmin∥x∥
此时采用不同范数作为优化目标,例如 ∥x∥1 或 ∥x∥2,将得到不同的结果
-
2-范数:向量 x 的必须位于直线 c1x1+c2x2=b 上,并且 ∥x∥2 最小,这等价于从原点开始膨胀一个 圆,直到撞到直线上的一个点,该点将是过原点向直线作垂线得到的 垂点
-
1-范数:向量 x 的必须位于直线 c1x1+c2x2=b 上,并且 ∥x∥1 最小,这等价于从原点开始膨胀一个 菱形,直到撞到直线上的一个点,该点将是直线在竖直轴上的 截距
矩阵范数 Matrix Norm
矩阵范数是对矩阵 大小 的度量,它与向量的范数类似,却又有所不同
2-范数
矩阵的 2-范数 是它的 第一奇异值,虽然他叫 2-范数,但实际上与向量的范数类比,矩阵的 2-范数 更像向量的 ∞-范数
∥A∥2=σ1
为何是这样或许不是很直观,实际上矩阵的 2-范数 是在寻找矩阵所代表线性变换的 最大拉伸系数,也就是说矩阵最大会将向量放大多少?显然这需要同时衡量向量的大小,自然而然的,我们也选择向量的 2-范数,于是这个问题可以表述为
∥A∥2=x∈Rnmax∥x∥2∥Ax∥2
也许我们会认为,这个系数是 最大特征值,而此时 x 应该是其对应的 特征向量,这几乎准确,但是我们不能忽略的是,如果这样选择,那么对于 非方阵 来说将无法定义其矩阵 2-范数
如果要定义一个所有矩阵都存在的 “特征” 版本,我们立刻想到了 奇异值 和 奇异向量,这也是为何矩阵的 2-范数 是它的 第一奇异值 (其对应的 x 是 第一右奇异向量 v1),因为这是该矩阵拉伸空间的最大倍率,其代表的 奇异向量 则是拉伸的最大方向
Frobenius 范数
该范数是一个重要的矩阵范数,甚至它看上去可能更像矩阵的 “2-范数”,因为它的定义是矩阵所有元素 平方和的平方根
∥A∥F=a112+⋯+a1n2+⋯+an12+⋯+amn2=σ12+⋯+σr2
如果对该范数也等于矩阵所有 奇异值平方和的平方根 感到意外,不妨写出 A 的 奇异值分解
A=UΣV⊤
奇异向量 组成的矩阵 U 和 V 都是代表纯 旋转/反射 的 正交归一矩阵 (酉矩阵),它们并不会改变向量的长度,所以唯一对 范数 的影响来自于 Σ,即所有 奇异值 组成的矩阵
核范数 Nuclear norm
该范数类似于向量的 1-范数,它是矩阵所有 奇异值 之和,所以会直接惩罚奇异值之和,促使很多奇异值被压到 0,从而鼓励 低秩
∥A∥N=σ1+⋯+σr
对于 机器学习 来说,这是一个重要的矩阵范数,因为算法会在所有潜在最小化权重中选出 核范数 最小的那个,因为在 “同样拟合训练数据” 的前提下,优先挑一个最低秩/最简单的解释一般是更好的,低秩=更少自由度=更强的共享结构=通常更好的泛化
带线性约束的最小范数问题
前面几章里,我们多次遇到 minimum norm solution 这个说法,尤其是在欠定系统
Ax=b
有无穷多个解的时候,伪逆会从所有可行解里挑出一个 2-范数 最小的解
而所谓 “最小范数” 并不是一个脱离范数选择的绝对概念
如果我们换一种范数来衡量 x 的大小,那么在同一个线性约束下,最优解也可能变成另一个点
这节用一个二维例子说明这件事
3x1+4x2=1
也就是所有可行向量
x=[x1x2]
都必须落在这条直线上
我们现在问:在这条直线上,哪个点离原点最近?
这个问题看起来很自然,但 “最近” 这两个字其实还没有定义完整,因为它取决于我们使用哪一种范数
同一个约束,三个最小化问题
黑板上比较的是下面三个问题
min∥x∥1,min∥x∥2,min∥x∥∞
它们都服从同一个约束
3x1+4x2=1
几何上,这相当于从原点开始不断放大某个范数的单位球,直到它第一次碰到这条直线
- 对 ℓ1 范数,单位球是菱形
- 对 ℓ2 范数,单位球是圆
- 对 ℓ∞ 范数,单位球是正方形
因为这三个单位球的形状不同,所以它们第一次碰到直线的位置也不同
用 ℓ1 范数
ℓ1 范数定义为
∥x∥1=∣x1∣+∣x2∣
对应的半径为 r 的范数球是
∣x1∣+∣x2∣≤r
它在二维里是一个菱形
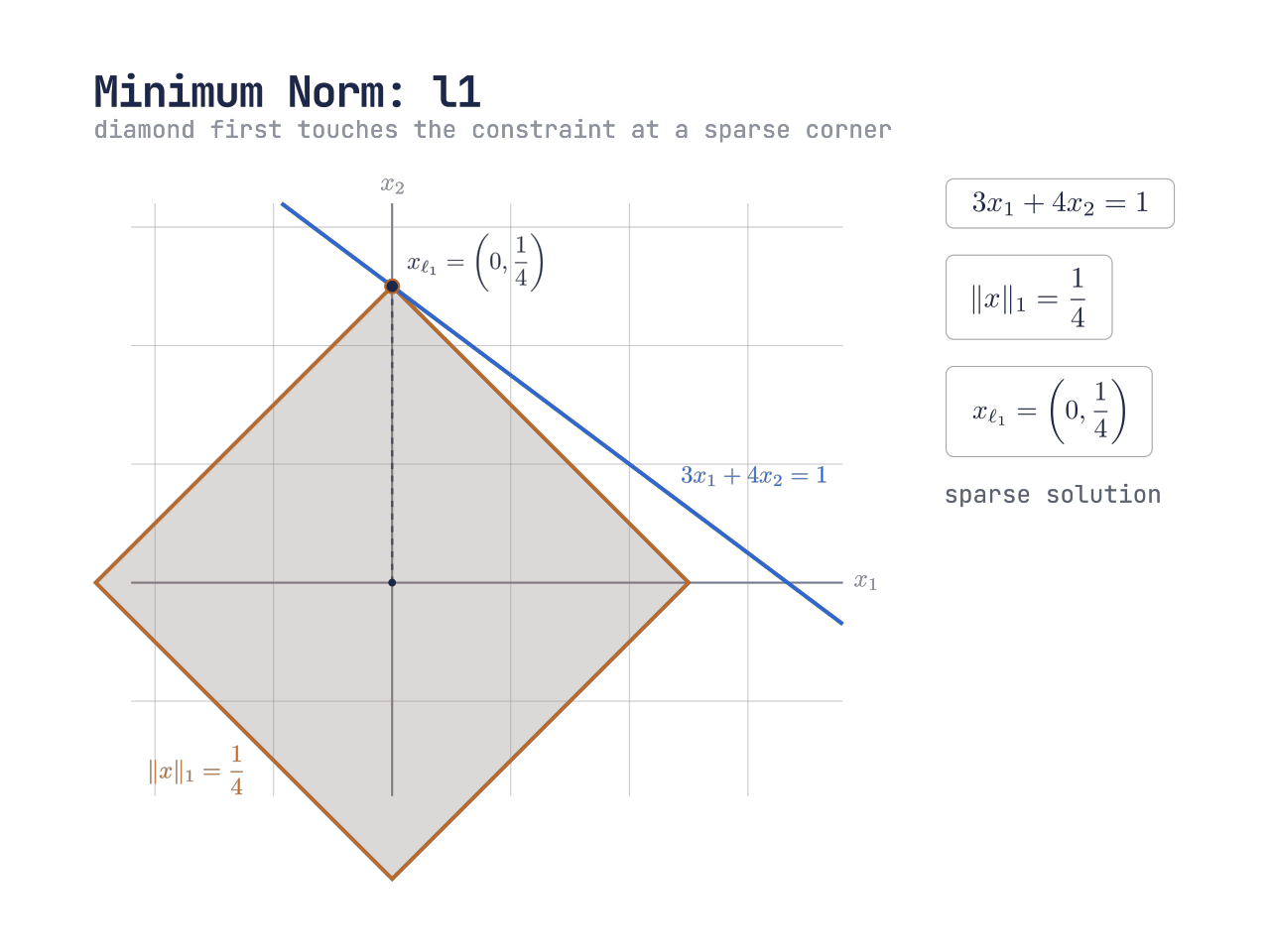
 ℓ₁ 范数球的尖角先碰到约束线,最优点落在坐标轴上,因此得到稀疏解。
ℓ₁ 范数球的尖角先碰到约束线,最优点落在坐标轴上,因此得到稀疏解。
现在我们要解的是
xmin∥x∥1s.t. 3x1+4x2=1
直观上,就是让这个菱形从原点开始放大,直到它第一次碰到直线
由于约束里 x2 的系数 4 比 x1 的系数 3 更大,所以若只用一个坐标来满足约束,使用 x2 会更 “省”
令
x1=0
则约束变成
4x2=1
因此
x2=41
所以 ℓ1 范数下的最优解是
xℓ1=[041]
这个解的特点是:它有一个分量等于 0,也就是 稀疏 sparse
这正是 ℓ1 范数经常和 sparsity 联系在一起的原因。它的单位球有尖角,而最优解常常出现在这些尖角上;在二维情形下,尖角恰好落在坐标轴上,因此容易得到某些分量为 0 的解
这也是 LASSO 和 ℓ1 regularization 常常产生稀疏解的几何来源
用 ℓ2 范数
ℓ2 范数定义为
∥x∥2=x12+x22
对应的范数球是圆
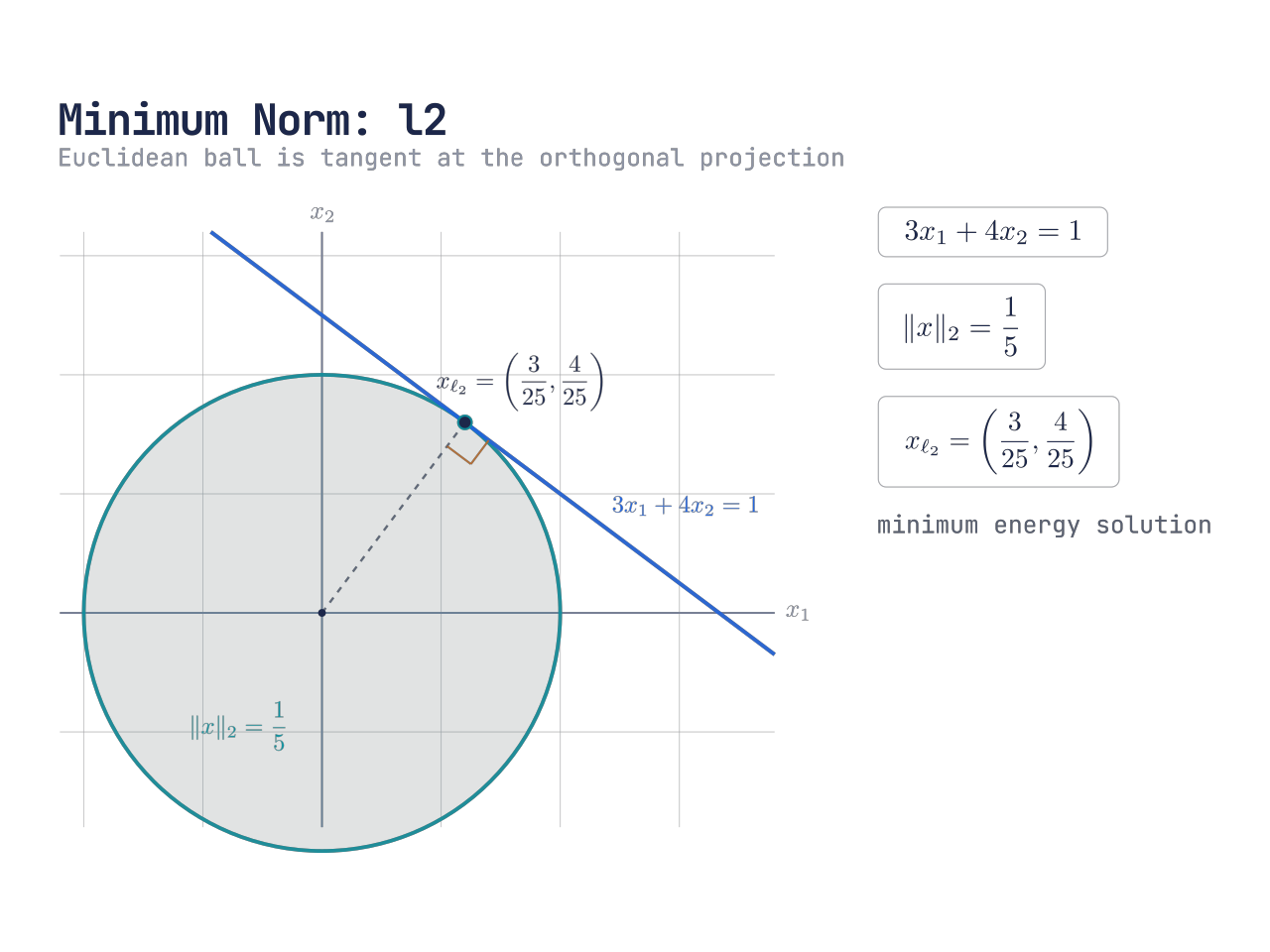
 ℓ₂ 范数球是圆;最优点是原点到约束线的垂足,也就是 Euclidean distance 最小的解。
ℓ₂ 范数球是圆;最优点是原点到约束线的垂足,也就是 Euclidean distance 最小的解。
此时问题变成
xmin∥x∥2s.t. 3x1+4x2=1
因为 ℓ2 距离就是普通的 Euclidean distance,所以这个最优点就是从原点到直线
3x1+4x2=1
的垂足
直线的法向量是
a=[34]
从原点到直线的垂足一定沿着法向量方向,所以可以设
x=λa=λ[34]
也就是
x1=3λ,x2=4λ
代入约束
3x1+4x2=1
得到
3(3λ)+4(4λ)9λ+16λ25λ=1=1=1
因此
λ=251
所以
xℓ2=[253254]
这正是伪逆和 least squares 里经常出现的那种 minimum norm solution
在更一般的情形下,如果
Ax=b
是欠定且一致的,那么伪逆
x=A†b
默认挑出的就是所有精确解里 ℓ2 范数最小的那个
用 ℓ∞ 范数
ℓ∞ 范数定义为
∥x∥∞=max(∣x1∣,∣x2∣)
对应的范数球是正方形
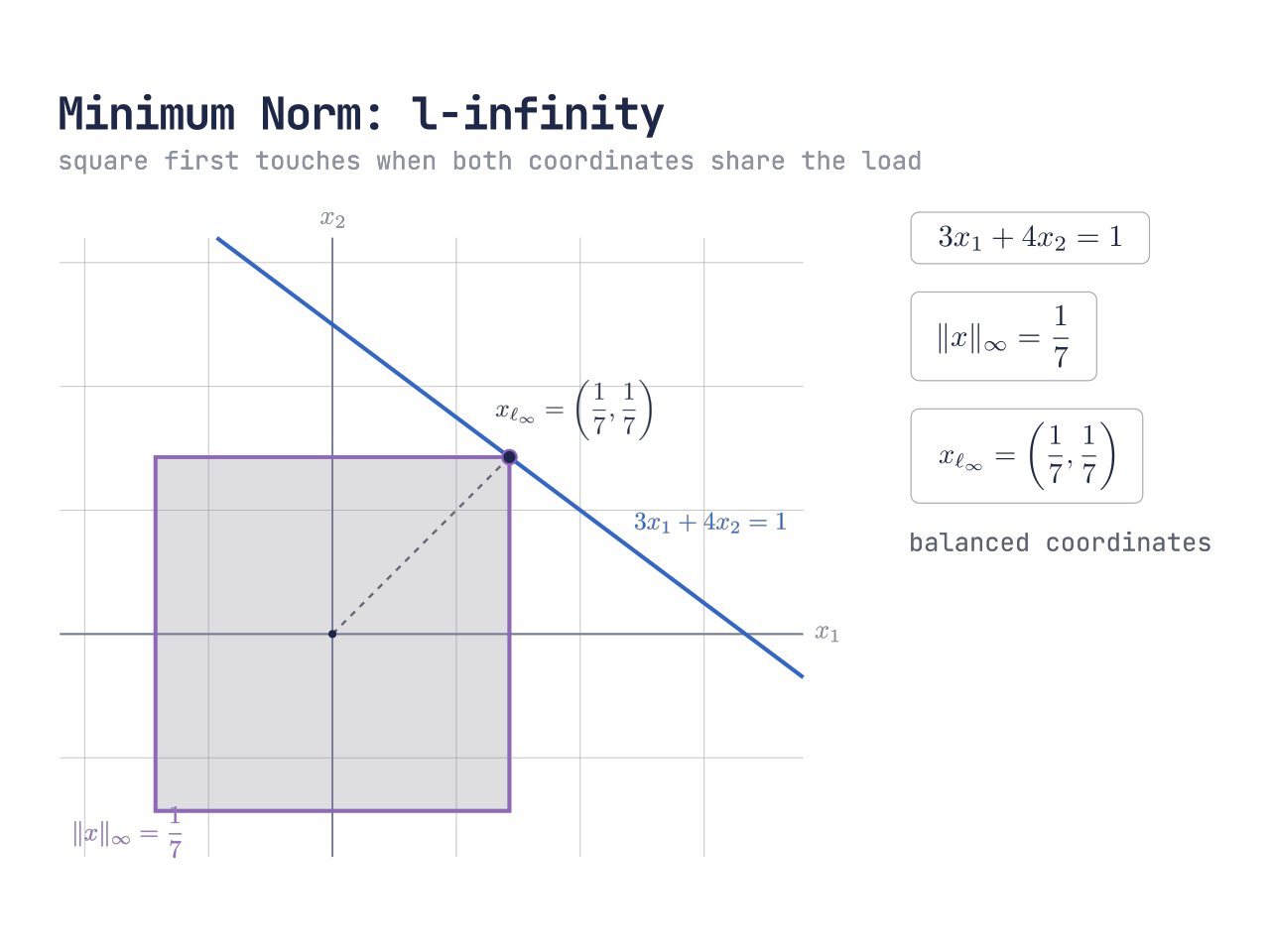
 ℓ∞ 范数球是正方形;最优点让两个坐标共同达到同一个上界,从而压低最大分量。
ℓ∞ 范数球是正方形;最优点让两个坐标共同达到同一个上界,从而压低最大分量。
此时问题变成
xmin∥x∥∞s.t. 3x1+4x2=1
也就是让
max(∣x1∣,∣x2∣)
尽可能小
设最优值为 t,那么约束可以写成
∣x1∣≤t,∣x2∣≤t
在这个例子里,两个系数 3 和 4 都是正数。为了让
3x1+4x2
尽快达到 1,同时又不让任何一个坐标超过 t,最优时两个坐标都会取到正的上界
x1=t,x2=t
代入约束得到
3t+4t7t=1=1
所以
t=71
因此 ℓ∞ 范数下的最优解是
xℓ∞=[7171]
ℓ∞ 范数的含义不是让整体能量最小,也不是鼓励稀疏,而是尽量压低最大的坐标分量
所以它倾向于让不同分量之间更加均衡,避免某一个坐标特别大
三个解的对比
同一个线性约束
3x1+4x2=1
在不同范数下给出的最小解分别是
ℓ1:xℓ1ℓ2:xℓ2ℓ∞:xℓ∞=[041]=[253254]=[7171]
它们分别体现了三种不同的偏好
- ℓ1 范数倾向于产生 稀疏解
- ℓ2 范数倾向于产生 最小能量解
- ℓ∞ 范数倾向于让 最大分量尽可能小
所以这张图想表达的核心是:
“最小范数解” 不是一个唯一概念。选择不同的范数,就等于选择不同的几何形状;而不同的几何形状,会在同一个可行集合上挑出不同的最优点。
特别地,ℓ1 范数的几何形状有尖角,因此它容易在坐标轴上取得最优解,从而产生稀疏性;而 ℓ2 范数的单位球是光滑圆形,所以它得到的是普通欧几里得意义下离原点最近的点